시간복잡도
알고리즘을 평가하는 데는 2가지 기준이 있다.
첫째, 알고리즘 실행시간에 해당하는 시간 복잡도
둘째, 메모리 사용량에 해당하는 공간 복잡도.
일반적으로 알고리즘을 평가할 때는 메모리의 사용량보다 실행 시간에 초점을 준다.
그러므로 시간 복잡도에 대해 정리해보겠다.
시간 복잡도란?
- 알고리즘이 다수의 입력값에 대한 문제를 얼마나 빠른 시간 내에 해결하는지 알 수 있는 척도(표기법).
알고리즘의 효율성을 판별할 수 있다.
시간 복잡도 표기법 3가지
1. 빅-오메가: 최고의 성능일 경우(Best Case)
2. 세타: 평균의 성능일 경우(Average Case)
3. 빅-오: 최악의 성능일 경우(Worst Case)
표기법의 3가지 중, 대부분 Big-O를 활용한다.
그 이유는, 평균의 성능 일 때가 좋아 보이지만 알고리즘이 복잡해질 수 록 평균적인 경우는 구하기 어렵다. 대신 최악의 성능일 경우는 구할 수 있기 때문에 Big-O를 활용한다.
Big O 표기법
최고차 항의 차수가 Big O가 된다.
EX)
Q(n)= n^2+13n+20 -> O(n^2)
Q(n)= n^7+n^5+n^2+523 -> O(n^7)
Q(n) = 15n^3 + 3n^2 +2n +100 -> O(n^3)
최고 차항의 차수가 Big O인 이유는 다른 항들의 값들이 아무리 커져봤자 최 고차항이 커지는 것에 못 미치기 때문이다.
시간 복잡도 성능
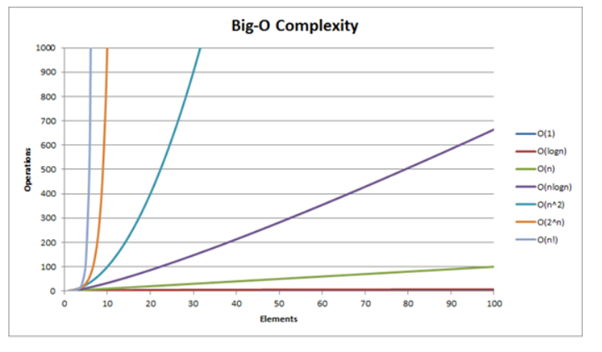
Big-O 성능 그래프
성능이 가장 좋은 순
1등: O(1)(배열의 요소를 참조할 때),
2등: O(logn),
3등: O(n),
4등: O(nlogn),
5등: O(n^2),
6등: O(n^3),
7등: O(2^n),
8등: O(n!)
보통 O(n^2) 이상의 복잡도를 가지는 알고리즘은 좋지 않다고 한다.
그리고 주요 성능별 정리해보자면,
O(1)
- 입력 데이터의 크기(데이터 양)와 상관없이 언제나 일정한 시간이 걸리는 알고리즘 (Constant Time)
O(log n)
- Binary search tree access(이진 검색), search(검색), insertion(삽입), deletion(삭제)
- 데이터양이 많아져도, 시간이 조금씩 늘어난다.
- 시간에 비례하여, 탐색 가능한 데이터양이 2의 n승이 된다.
- 문제를 해결하는데 필요한 단계들이 연산마다 특정 요인에 의해 줄어든다.
- 만약 입력 자료의 수에 따라 실행 시간이 이 log N의 관계를 만족한다면 N이 증가함에 따라 실행시간이 조금씩 늘어난다. 주로 커다란 문제를 일정한 크기를 갖는 작은 문제로 쪼갤 때 나타나는 유형이다.
O(n)
- 입력 데이터의 크기에 비례해서 처리시간에 걸리는 알고리즘을 표현할 때 사용 (Linear Time)
- 데이터양에 따라 시간이 정비례한다.
- Linear search, for 문을 통한 탐색을 생각하면 된다.
O(n^2)
- 데이터양에 따라 걸리는 시간은 제곱에 비례한다. (효율이 좋지 않음, 사용 X)
- 해당 유형은 이중 Loop내에서 입력 자료를 처리하는 경우에 나타난다. N값이 큰 값이 되면 실행 시간은 감당하지 못할 정도로 커지게 된다.
문제를 해결하기 위한 단계의 수는 입력값 n의 제곱
참고자료
feel5ny.github.io/2017/12/09/CS_01/
velog.io/@bathingape/Time-Complexity%EC%8B%9C%EA%B0%84%EB%B3%B5%EC%9E%A1%EB%8F%84